


*本文为万向区块链“融合创新”系列行业研究报告。作者:万向区块链首席经济学家邹传伟博士。
由万向区块链实验室主办的第六届区块链全球峰会,以“融合创新”为主题,旨在广邀国内外知名技术专家、学者、企业家共聚一堂,探讨区块链与其他技术的融合创新,以及如何以区块链技术为驱动力,推动不同行业的融合创新,共创良好地技术生态效应。
万向区块链将在峰会开始前的这段时间内,不定期推出“融合创新”系列行业研究报告,深度解读在新基建和数字化迁徙背景下,区块链如何与其它技术融合发展,发挥信息基础设施应有的作用。

研究背景
在此前的研究文章《对数据要素的特征、价值和配置机制的初步研究》,讨论了数据要素估值面临的难题。
第一,同样数据对不同人的价值可以大相径庭。不同人的分析方法不一样,从同样数据中提炼出的信息、知识和智慧可以相差很大。不同人所处的场景和面临的问题不一样,同一数据对他们起的作用也不一样。不同制度和政策框架对数据使用的限定不一,也会影响数据价值。
第二,数据要素价值随时间变化。数据有时效性,数据折旧是一个普遍现象。数据还有期权价值。
第三,数据会产生外部性。同一数据对个人和社会的价值可以不一样。数据与数据结合的价值,可以不同于它们各自价值之和。
总的来说,目前的数据要素估值方法,主要包括成本法、收入法、市场法和问卷调查法,尽管在一定维度上都有合理性,但在理论上和实施中都有不少问题。
数据要素市场在发展早期,参与者将以机构为主。但如果没有合适的估值框架,一个由机构参与者主导的市场也不一定能发展起来。鉴于现有数据要素估值方法面临的问题,我提出一个新的估值框架,称为DataRank。
DataRank概述
DataRank的分析单元是数据,也就是一组观察的集合。观察对象包括物体、个人、机构、事件以及它们所处环境等,并基于一系列视角、方法和工具进行。对每个新进入数据要素市场的数据单元,DataRank先对其提炼出一系列Tag,再给出初始的datarank值,作为估值起点。然后,DataRank根据数据单元实际被调用的情况,动态调整并持续更新datarank值。
DataRank有以下核心特征。第一,用统一尺度评估不同数据单元价值高低。尽管datarank值没有量纲,但根据市场供需情况和交易价格,不难从datarank值折算出货币标价的数据估值。
第二,对不同的数据使用者而言,datarank值相当于参考基准。他们根据datarank值提供的信息,决定是否调用数据单元。数据单元被调用的情况,将反映到datarank值的动态调整中。在其他条件一样的情况下,某一数据单元被调用得越多,其datarank值上调也越多。换言之,DataRank不试图一劳永逸地给出数据单元估值,而是在一个动态过程中不断评估数据单元价值,并充分考虑数据单元在数据要素市场上的表现。DataRank能兼容同一数据对不同人以及在不同时点上的价值可以差别很大的情况。
理论上,数据对使用者的价值,只能在事后评估,也就是使用完数据后,才能准确评估数据价值。事前只能去推测或估算数据价值。因此,在一定意义上,数据估值类似“赌石”。翡翠开采出来后,原石有一层风化皮包裹着,无法知道其内的好坏,须切割后才能知道翡翠的质量。有经验的赌石师可以根据原石外观推测内部情况。datarank值相当于为数据“赌石”提供了参考。
第三,多个数据单元一起被调用时,DataRank能考虑数据之间的协同效应。换言之,在其他条件一样的情况下,与一个datarank值高的数据单元一起被调用,能增加自身的datarank值。
最后需要看到的是,DataRank还为数据要素市场的组织形式提供了参考。在数据要素市场上,数据使用者在寻找合适的数据单元时,会通过关键词来检索。关键词就对应着Tag,数据单元展示的优先顺序可以依据datarank值。
Tag与datarank值的初始赋值
数据单元的Tag来自以下维度:
-
数据类型,比如个人身份信息、衣食住行等方面行为数据以及金融资产和交易数据。
-
数据涉及的样本分布、时间范围和变量类型等。
-
数据容量,比如样本数、变量数、时间序列长度和占用的存储空间等。
-
数据质量,比如样本是否有代表性,数据是否符合事先定义的规范和标准,观察的颗粒度、精度和误差,以及数据完整性(比如是否有数据缺失情况)等。
-
数据的时效性。
-
数据来源。有些数据来自第一手观察,有些数据由第一手观察者提供,还有些数据从其它数据推导而来。数据可以来自受控实验和抽样调查,也可以来自互联网、社交网络、物联网和工业互联网等。数据可以由人产生,也可以由机器产生。数据可以来自线上,也可以来自线下。
假设共提炼出P个Tag,依次记为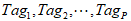 。每个Tag赋予一定权重。为简便起见,也用
。每个Tag赋予一定权重。为简便起见,也用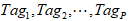 表示这些Tag的权重。
表示这些Tag的权重。
对一个新进入数据要素市场的数据单元,在每个Tag上对其打分,得分依次为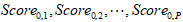 。这个数据单元的初始datarank值是
。这个数据单元的初始datarank值是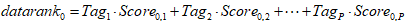 。
。
假设在这个新数据单元进入前,市场中共有N个数据单元。用下标i表示一个代表性的数据单元(i取值从1到N)。权重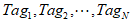 ,可以用线性回归来估计:
,可以用线性回归来估计:
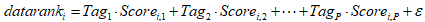
其中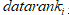 是被解释变量,
是被解释变量,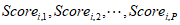 是解释变量,
是解释变量,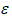 表示误差项。
表示误差项。
datarank值的动态调整
有两种可以考虑的datarank值的动态调整机制。
(一)按数据调用次数调整
假设用户在一次调用中,同时调用了J个数据单元,编号依次为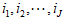 。用
。用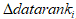 表示因这次调用对数据单元
表示因这次调用对数据单元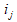 的datarank值的上调:
的datarank值的上调:
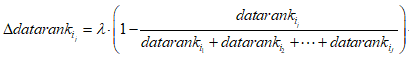
其中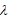 表示调用奖励系数。
表示调用奖励系数。
以上调整公式背后的直觉非常简单:一是与datarank值高的数据单元一起被调用,更有助于提高自身的datarank值,也就是“近朱者赤”;二是在其他条件一样的情况下,被调用次数越多,datarank值上调越多,也就是“多劳多得”。
因为每次数据调用都要根据datarank值付费,通过调用“刷单”来提高某一数据单元的datarank值,会付出比较高的成本。这样能保障DataRank框架不会被操纵。
(二)按数据单元间联系调整
这个调整机制本质上类似Google的PageRank算法(见附件)。
把每个数据单元视为一个节点。如果两个数据单元曾被一起调用过,就认为它们之间存在一条边,只不过这条边有权重。比如,考虑某一数据单元a,它与数据单元b、c和d分别一起调用过5、2和3次。那么,从a到b、c和d的有向边的权重就分别是0.5、0.2和0.3。这样,数据单元和它们之间的联系就构成了一个有向图。如果赋予有向边的权重以概率含义,那么数据单元之间的调用关系就可以用马尔科夫过程来描述,有向边的权重就是转移概率。
按照与PageRank类似的方法,分析这个马尔科夫过程的稳态分布,就得到datarank值。
附件:PageRank算法简介
在Google之前出现过很多搜索引擎,其中大部分都是利用网络爬虫从互联网上抓取数据,然后通过倒排索引方式列出每个页面所包含的词项。当用户提交一个搜索查询(search query)时,所有包含这些词项的网页会从倒排索引中抽取出来,并按照能够反映页面内词项作用的某种方式排序。因此,如果词项出现在网页头部,该网页的相关性比词项出现在普通正文中的网页更高,而且词项出现次数越多,网页相关性越高。在这种情况下,词项作弊(term spam)大量出现,一些人通过修改网页的方式(比如大量重复某一关键词)欺骗搜索引擎,让它们相信一个本来不相关的页面。PageRank算法就是针对词项作弊开发的,主要有两项创新。
第一,模拟互联网冲浪者的行为。这些假想的冲浪者从随机网页出发,每次从当前页面随机选择出链前行,该过程可以迭代多步。最终,这些冲浪者会在页面上汇合。较多冲浪者访问的页面的重要性被认为高于那些较少冲浪者访问的页面。网页的这种重要性就用PageRank值来衡量。Google在决定查询应答顺序时,会将PageRank值较高的页面排在前面。
第二,在判断网页内容时,不仅只考虑网页上出现的词项,还考虑指向该网页的链接中或周围所使用的词项。这里面隐含的假设是:网页的所有者倾向于链接他们认为较好或有用的网页,而不愿链接那些糟糕或无用的网页;尽管作弊者很容易在它们控制的网页中增加虚假词项,但是在指向当前网页的网页上添加虚假词项却不那么容易。(针对链接分析出现了链接作弊,即为提高某个或者某些特定网页的PageRank值而构建一个网页集合,称为垃圾农场。相应地,出现了一些反作弊方法,比如TrustRank和垃圾质量等。)
在上述两项创新下,PageRank算法实际上把互联网视为一个有向图,其中网页是图中节点,如果两个网页之间存在一条或多条链接,那么它们之间就存在一条有向边。PageRank算法为模拟互联网冲浪者的行为,赋予这些有向边以转移概率(transition probability)含义。比如,假设冲浪者当前处在页面A,而页面A有3条出链分别指向页面B、C和D。可以认为,冲浪者下一步以各1/3的概率分别访问B、C和D,但继续访问A的概率为0。这样,冲浪者在互联网上的行为就可以用马尔可夫过程(Markov process)来刻画。
假设共有N个页面,其集合记为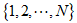 ,是马尔可夫过程的状态空间。用
,是马尔可夫过程的状态空间。用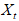 表示冲浪者在时刻所处页面,
表示冲浪者在时刻所处页面,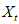 是一个随机变量,取值在
是一个随机变量,取值在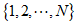 之中。随机变量序列
之中。随机变量序列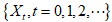 就是一个随机过程。在PageRank算法中,该随机过程满足马尔可夫性质(直观描述是,给定现在,过去和未来不相关):
就是一个随机过程。在PageRank算法中,该随机过程满足马尔可夫性质(直观描述是,给定现在,过去和未来不相关):
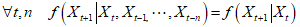
其中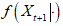 表示
表示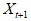 的条件概率分布。
的条件概率分布。
因此,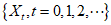 是一个马尔可夫过程,可以用转移概率矩阵(transition matrix)来刻画其动态变化。用NxN矩阵P表示转移概率矩阵,其第i行第j列元素
是一个马尔可夫过程,可以用转移概率矩阵(transition matrix)来刻画其动态变化。用NxN矩阵P表示转移概率矩阵,其第i行第j列元素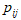 的含义是:
的含义是:
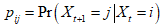
用Nx1矩阵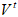 表示
表示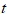 时刻冲浪者在互联网上位置分布,其第i个分量
时刻冲浪者在互联网上位置分布,其第i个分量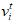 的含义是:
的含义是:

那么,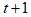 时刻冲浪者在互联网上位置分布
时刻冲浪者在互联网上位置分布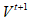 满足:
满足:
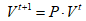
如果互联网对应的有向图是强连通的(strongly connected),即从任一节点出发可到达其他节点,并且不存在终止点(即不存在没有出链的节点),那么不管冲浪者初始时刻在互联网上位置如何分布,足够长时间后,他的位置分布将逼近一个稳态分布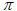 。严谨表述是:
。严谨表述是:

稳态分布满足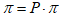 (即从稳态出发,下一个时刻仍是稳态),因此
(即从稳态出发,下一个时刻仍是稳态),因此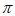 实际上是矩阵P的特征向量(eigenvector),对应的特征值(eigenvalue)为1。
实际上是矩阵P的特征向量(eigenvector),对应的特征值(eigenvalue)为1。
的第i个分量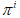 表示在稳态时,冲浪者处于第i个页面的概率,也就是第i个页面的PageRank值。
表示在稳态时,冲浪者处于第i个页面的概率,也就是第i个页面的PageRank值。
现实中,互联网对应的有向图一般不具有强连通特征。比如,可能存在没有任何出链的终止点,也可能存在一组网页,虽然它们都有出链但这些出链不会指向这组网页之外的其他网页。PageRank算法通过修正转移概率矩阵来解决这些问题,比如“抽税”法,就不详述了。
本文来自万象区块链,经授权后发布,本文观点不代表星空财经BlockGlobe立场,转载请联系原作者。

相关推荐
-
Web3品牌如何用数据化叙事打动市场?Gitcoin Grants案例分析 | 数据驱动公关
-
德鼎创新基金合伙人王岳华:使用同态加密实现比特币 Rollup 与隐私保护
-
Arthur Hayes 最新预测:比特币 25W,以太坊 1W
-
颠覆者Robinhood:推动金融服务民主化|Disruptors Unplugged
-
金融创新「最短路径」:RWA如何引领金融基础设施重构?|NextMarket
-
蔡崇信谈领导力:成长型思维、年轻人赋能,以及开源AI的力量|The Thought Stack
-
华尔街上链!代币化股票能否续写稳定币的史诗传奇?
-
香港加密宣言2.0“LEAP”框架速览:RWA、金融资产代币化、稳定币、人才及项目支持
-
从泡泡玛特到比特币:麦刚「风口之外」的独立投资人哲学|星空ProShare
-
稳定币的全球竞赛:从合规背书到机构爆发,亚洲领跑下一轮增长
-
Web3出海|阿联酋及迪拜、阿布扎比加密监管政策简明框架
-
欧洲各国加密税制全景:Web3税务合规与机遇洞察|环球政策